Governance & Observability
The patterns that let humans trust the agent over time.
38 patterns in this book. · Updated
{kind=link}
When to reach for each
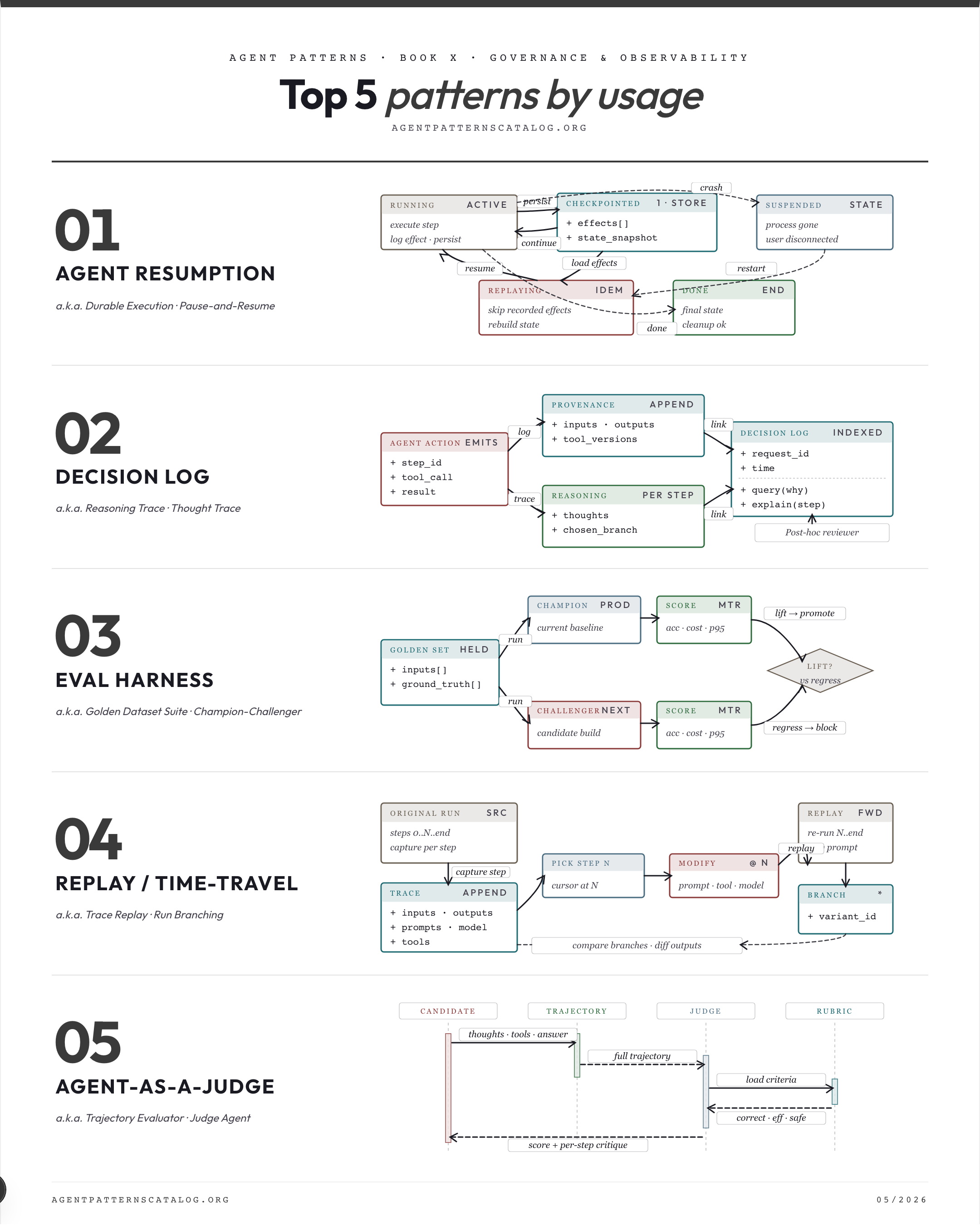
01. Agent Resumption Persist agent execution state so a long-running run survives restarts, deploys, or user disconnects. Best for: Agent runs are long enough that restarts, deploys, or disconnects would lose meaningful work. Tradeoff: Checkpoint storage cost. Watch for: Runs complete in seconds and can simply be retried from scratch.
02. Eval Harness Run a held-out dataset against agent versions to detect regressions and measure improvement. Best for: A change that 'feels better' is regressing quality silently in your system. Tradeoff: Dataset bias means high scores can hide real-world failures. Watch for: No expected outputs exist (open-ended creative tasks) and scoring would be subjective.
03. Decision Log Persist the agent's reasoning trace alongside its actions so post-hoc review can explain why. Best for: Action-only logs leave you unable to explain why the agent did something. Tradeoff: Storage and privacy implications. Watch for: Reasoning logs would be retained without any review process consulting them.
04. LLM-as-Judge Use an LLM to score open-ended outputs against rubric criteria when no exact-match metric applies. Best for: Open-ended outputs need automated regression detection without a reference answer. Tradeoff: Judge biases skew scores in subtle ways. Watch for: An exact-match or reference metric already grades the task.
05. Replay / Time-Travel Re-run a past agent trace from any step with modified inputs/prompts/tools to debug or branch. Best for: Agent runs are non-deterministic and incidents need reproducible debugging. Tradeoff: Trace storage overhead. Watch for: Trace storage cost outweighs the value of replay (low-stakes ephemeral runs).
All patterns in this book
Agent Resumption
×38Persist agent execution state so a long-running run survives restarts, deploys, or user disconnects.
Eval Harness
×17Run a held-out dataset against agent versions to detect regressions and measure improvement.
Decision Log
×14Persist the agent's reasoning trace alongside its actions so post-hoc review can explain why.
LLM-as-Judge
×10Use an LLM to score open-ended outputs against rubric criteria when no exact-match metric applies.
Replay / Time-Travel
×7Re-run a past agent trace from any step with modified inputs/prompts/tools to debug or branch.
Provenance Ledger
×6Log every agent decision and state change with enough metadata to explain or reverse it later.
Agent-as-a-Judge
×6Evaluate an agent's full trajectory (steps, tool calls, intermediate states) by another agent rather than scoring only the final output.
Lineage Tracking
×5Track which prompt version, model version, and data sources produced each agent output.
Shadow Canary
×4Run a candidate agent version in shadow alongside the champion, comparing outputs without affecting users.
Dual Evaluation (Offline + Online)
×4Run two parallel evaluation tracks — offline benchmark gates before deploy AND online production-traffic monitoring after — so drift is caught even when pre-deploy benchmarks pass.
Cost Observability
×3Surface per-request, per-user, and per-feature cost and token consumption to operators in near-real-time.
Eval as Contract
×3Treat the eval suite as the contract the agent must satisfy; releases ship only if evals pass.
Prompt Versioning
×3Treat prompts as immutable, hashed, semver'd artefacts in a registry; deploy and roll back like code.
Agent Middleware Chain
×3Wrap every model call, tool call, and memory access in a composable pre/execute/post interceptor pipeline so cross-cutting concerns attach without touching agent or orchestrator code.
Durable Workflow Snapshot
×3Capture workflow execution state as a snapshot in a pluggable storage provider so a paused run can resume across deployments, process restarts, and host crashes.
Re-Contact-Subtracted Resolution Gate
×3Gate a support agent on a re-contact-subtracted resolution rate so an interaction that merely ends the session is never reported as a resolved one.
Sandbox Escape Monitoring
×3Treat sandbox boundary violations as telemetry; alert on syscalls, network egress, or filesystem writes outside expected scope.
Journaled LLM Call
×2Record the output of every non-deterministic step on first execution and replay that recorded value during crash-recovery instead of re-invoking the model.
Production Failure Triage Loop
×2Sort every production agent failure into a small fixed taxonomy and bind each class to a set remediation path, so fixes are dispatched mechanically and the monitor-to-fix loop stays fast enough to ga…
Sampled Prompt Trace Eval
×2Capture full prompt/response/metadata traces from production into a monitoring dataset, but only run LLM-judge evaluation on a random sample so monitoring cost stays bounded as traffic grows.
Scorer Live Monitoring
×2Score agent outputs asynchronously in production with non-blocking scorers that observe, alert, and log but do not regenerate the output.
Agent Evaluator
×1A dedicated agent or harness whose sole job is running tests against another agent's outputs to evaluate performance; distinct from eval-harness (offline batch) and llm-as-judge (per-output).
Agent Factory
×1Manufacture agent instances from a versioned template that renders model, tools, and prompt atomically, with registry-backed identities, so a fleet stays consistent and one template change propagates…
Bayesian Bandit Experimentation
×1Replace fixed-split A/B tests between agent variants with a bandit that dynamically reallocates traffic toward better-performing variants based on observed reward, bounding regret from bad variants.
Decision Token
×1Mint a self-contained record at the moment a consequential action executes, bundling the rule that fired, the exact data read, the conclusion reached, and the authorizing identity.
Intermediate Artifact Evaluation
×1Evaluate intermediate artifacts (plans, tool-call traces, guardrail reactions) not only final outputs; isolates failure to a specific pipeline node.
Managed Agent Runtime
×1Offer the agent loop itself as a managed cloud primitive so a caller supplies a model, system prompt, and tools and the platform runs the orchestration in an isolated, session-scoped runtime.
Own Your Prompts (12-Factor Agents)
×1Every prompt in a production agent is versioned, tested, and owned by the team in the application repo — never inherited as a framework default.
Scaffold Ablation on Model Upgrade
×1On each model upgrade, treat every harness component as an encoded assumption about a model weakness and ablate the components the new model no longer needs, gated by evals.
Deontic Token Delegation
×1Reify obligations, permissions, and prohibitions as transferable deontic tokens that agents pass along the delegation chain with provenance, so duty and accountability transfer with the work, not onl…
Multi-Principal Welfare Aggregation
×1When an agent serves multiple humans with conflicting preferences, declare the aggregation rule explicitly rather than letting it be implicit in the prompt or fine-tune.
Agentic Golden Path
Constrain an agent to the platform's curated golden path of living, machine-readable standards and check for drift as it works, so its output is compliant by construction rather than corrected later.
Compliance-Certified Launch Gate
Require an external regulator to certify the generative service against a published content-safety standard before it may serve the public, forcing the standard's controls into the build as a re-cert…
Postmortem Pattern Mining
Mine a corpus of thousands of written postmortems through a staged model pipeline that summarises, classifies, analyses, and aggregates so that recurring incident causes surface as one short report.
Rigor Relocation
Relocate verification rigor from the model loop to surrounding scaffolding (evals, judges, decision logs, policy gates) so failures are caught by the wrapper rather than the agent.
Silent Pilot-to-Production Promotion
Anti-pattern: let a well-performing pilot quietly expand in scope until it is a de facto production decision system, while keeping the 'pilot' label so it never trips the go-live governance gate.
Attention-Manipulation Explainability
Surface which input tokens caused a given output by perturbing attention across all transformer layers and measuring the resulting change in output probability, producing a per-token relevance map al…
Determinism-Tiered Replay Gate
Classify an agent into a reproducibility tier by re-running identical inputs, require the strictest decision-determinism tier for regulated decisions, and gate deployment and validation-sample size o…