Memory
What the agent remembers, where, for how long.
34 patterns in this book. · Updated
{kind=link}
When to reach for each
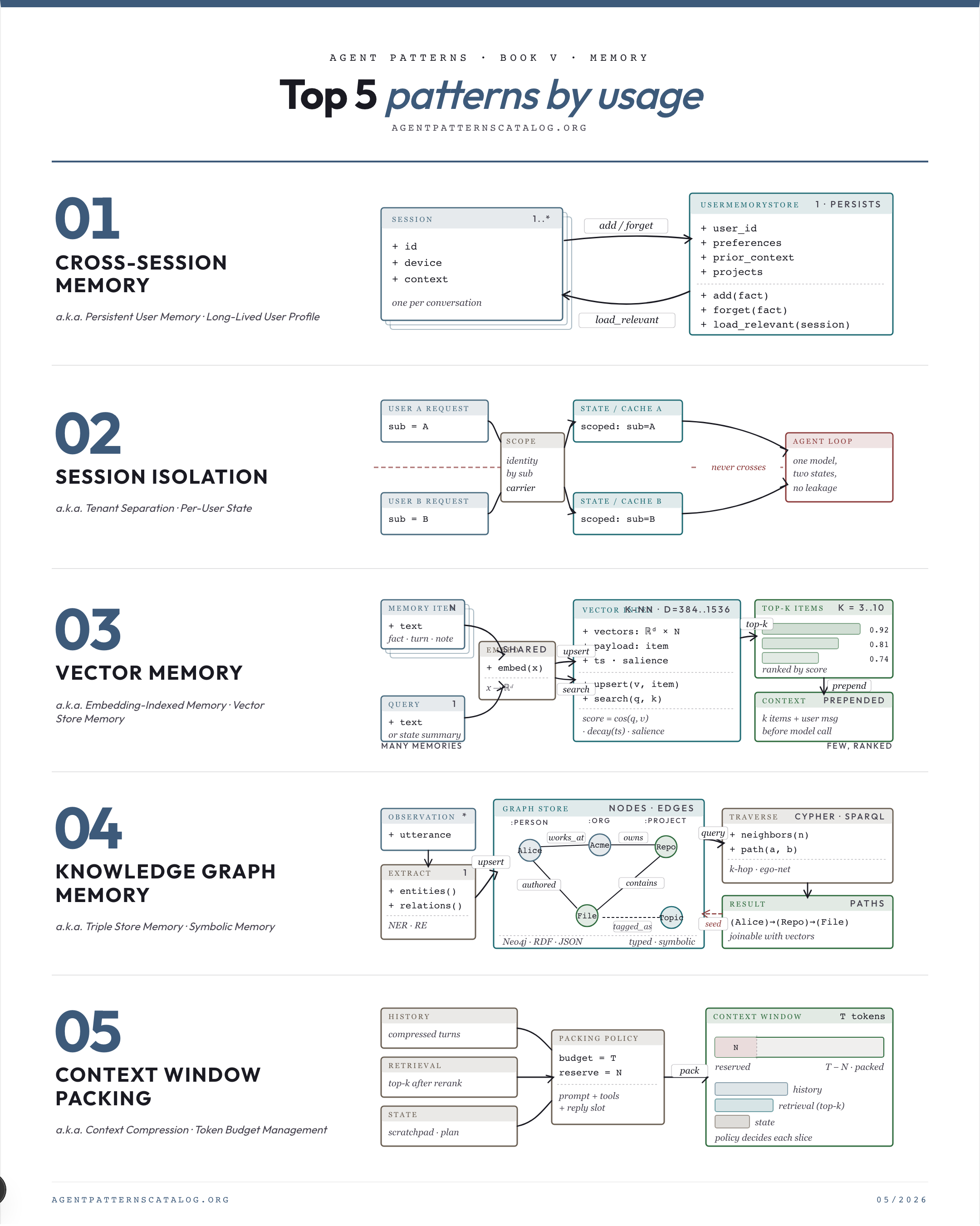
01. Cross-Session Memory Persist user-specific facts, preferences, and prior context across all sessions, threads, and devices. Best for: Per-thread memory loses important user-specific facts between sessions and the assistant feels amnesic. Tradeoff: Privacy obligations. Watch for: Sessions are deliberately stateless for privacy or compliance reasons.
02. Session Isolation Keep one user's session state and memory unreachable from another user's agent. Best for: Multiple users share an agent backend and cross-user leaks are unacceptable. Tradeoff: Loss of cross-user cache benefits. Watch for: The agent serves a single user or fully trusted tenant.
03. Vector Memory Store memories as embeddings in a vector index and retrieve the most semantically similar items at query time. Best for: Long-running agents accumulate facts whose relevance is best judged by similarity. Tradeoff: Misses purely temporal queries ('what did I do yesterday?'). Watch for: Memory is small and a typed key-value store would serve better.
04. Knowledge Graph Memory Persist agent memory as entities and relations in a structured graph so symbolic queries (path, neighbour, type) become possible. Best for: The agent must answer relational queries (path, neighbour, type) over remembered entities. Tradeoff: Extraction quality bounds graph quality. Watch for: Memory is unstructured text where vector search is sufficient.
05. Context Window Packing Choose what fits in the context window each turn given a fixed token budget. Best for: Naive concatenation overflows the context window for realistic inputs. Tradeoff: Complexity of the packing logic. Watch for: Inputs are small and always fit comfortably in the window.
All patterns in this book
Cross-Session Memory
×22Persist user-specific facts, preferences, and prior context across all sessions, threads, and devices.
Session Isolation
×18Keep one user's session state and memory unreachable from another user's agent.
Vector Memory
×7Store memories as embeddings in a vector index and retrieve the most semantically similar items at query time.
Knowledge Graph Memory
×6Persist agent memory as entities and relations in a structured graph so symbolic queries (path, neighbour, type) become possible.
Context Window Packing
×5Choose what fits in the context window each turn given a fixed token budget.
Five-Tier Memory Cascade
×5Stage agent memory across sensory, working, short-term, episodic, and long-term tiers with explicit promotion and decay between them.
MemGPT-Style Paging
×4Treat the LLM context window as RAM and external storage as disk, with the model issuing tool calls to page memory in and out.
Episodic Summaries
×3Compress past episodes into summaries that preserve gist while shedding token cost.
Short-Term Thread Memory
×3Carry the relevant slice of conversation context across turns within a session.
Append-Only Thought Stream
×3Make the agent's thought log append-only so the agent cannot rewrite its own history.
Episodic Memory
×2Record past events as time-stamped first-person experiences the agent can recall later, separately from extracted facts (semantic) and learned how-to (procedural).
Filesystem as Context
×2Use the filesystem as the agent's externalized working memory, writing plans, notes, and large tool outputs to files, dropping them out of the live window, and re-reading on demand.
Reasoning Trace Carry-Forward
×2For reasoning models that emit a separate reasoning trace, preserve that trace in context across the same logical task episode (across tool-call/result turns) but drop it at user-turn boundaries.
Semantic Memory
×2Maintain a dedicated store of what the agent holds to be true about the user and the world, separate from event records (episodic) and learned how-to (procedural).
World-Model Graph Memory
×2Memory store structured as a typed entity-relation graph used as the agent's authoritative world model for planning — not only for retrieval.
Adaptive Memory Decay
×1Give each long-term memory item a retention score that decays over time through a function modulated by relevance, access frequency, and recency, so unreinforced items fade or fuse while items that a…
Agentic Memory
×1Expose memory management as first-class tool actions (ADD, UPDATE, DELETE, RETRIEVE, SUMMARY, FILTER) the LLM chooses at every step, trained end-to-end so short-term and long-term memory live under o…
Context Compaction
×1When the context window nears its limit, replace the older conversation span with a model-written digest that preserves decisions, commitments, and active constraints while discarding noise, so the a…
Procedural Memory
×1Maintain a third agent memory type alongside episodic (past events) and semantic (facts): procedural memory captures *learned how-to* — reusable skills, workflows, and self-rewritten system instructi…
Salience Attention Mechanism
×1Score every candidate memory item with a weighted salience function so each tick attends to a small, relevant top-k subset rather than re-reading all memory.
Co-Located Memory Surfacing
×1Surface relevant persistent memories proactively when the human mentions a concrete entity the agent has prior knowledge of, so the human does not bear the burden of remembering to ask.
Hippocampal Rehearsal
×1Lift archived memory items back into short-term tiers when something re-attends to them.
Now-Anchoring
×1Ground the agent's reasoning in the current absolute time without requiring tool calls, so every reply is implicitly time-aware.
Self-Corpus Vocabulary
×1Mine a small bounded vocabulary from the agent's own writing and cache it as the conceptual axis for scoring new thoughts, so relevance reflects the agent's actual frame rather than a generic embeddi…
Sleep-Time Compute
×1During idle or downtime, run the model offline against the user's standing context to pre-compute dense summaries and likely future answers, so test-time latency and cost drop when the user actually…
Information Chunking for Agent Memory
Structure inputs into digestible topical segments (chunks) before feeding to short-term memory rather than throwing the full input at the model; reduces overload and increases accuracy (~40% improvem…
Memory-Type Storage Specialization
Use different storage technologies optimized per memory type — fast in-memory stores (Redis-class) for episodic, vector databases (Pinecone/Weaviate) for semantic, relational or workflow engines for…
Scratchpad
Give the agent a writable scratch space for intermediate notes that informs later turns but does not pollute the response.
Context Window Dumb-Zone Cap
Hold context-window utilization below a working threshold (~40%) to keep the model out of the 'dumb zone' where it begins ignoring earlier instructions and hallucinating.
Three Layers of Agentic AI Memory
Architect agent memory as three integrated concentric layers — Short-Term Memory (outer), Long-Term Memory (middle), Feedback Loops (core) — operating together as a unit rather than as separable opti…
Unstructured Human Capture Layer
Keep a human-authored raw dump layer that the agent may read but never edit, and confine all structuring to a separate derived layer, so half-formed human thought survives as durable context.
Context Folding
Let the agent branch into a temporary sub-context for a subtask and fold it back into a short summary on completion, so a long-horizon task stays within a small active window.
Landmark Attention
Long-context attention mechanism placing sparse landmark tokens across very long inputs so the model jumps directly to relevant sections via landmark lookup rather than scanning linearly.
Test-Time Memorization (Titans)
Memory module that learns at inference time by incorporating recent inputs into its parameters during the session rather than relying solely on pre-trained weights.