Reasoning
How the model thinks before acting.
19 patterns in this book. · Updated
{kind=link}
When to reach for each
01. Extended Thinking Spend a configurable budget of internal reasoning tokens before producing a user-visible answer. Best for: The provider exposes a reasoning-budget API and you want to tune effort per request. Tradeoff: Cost spikes with budget. Watch for: Static prompt-based chain-of-thought already meets quality and cost targets.
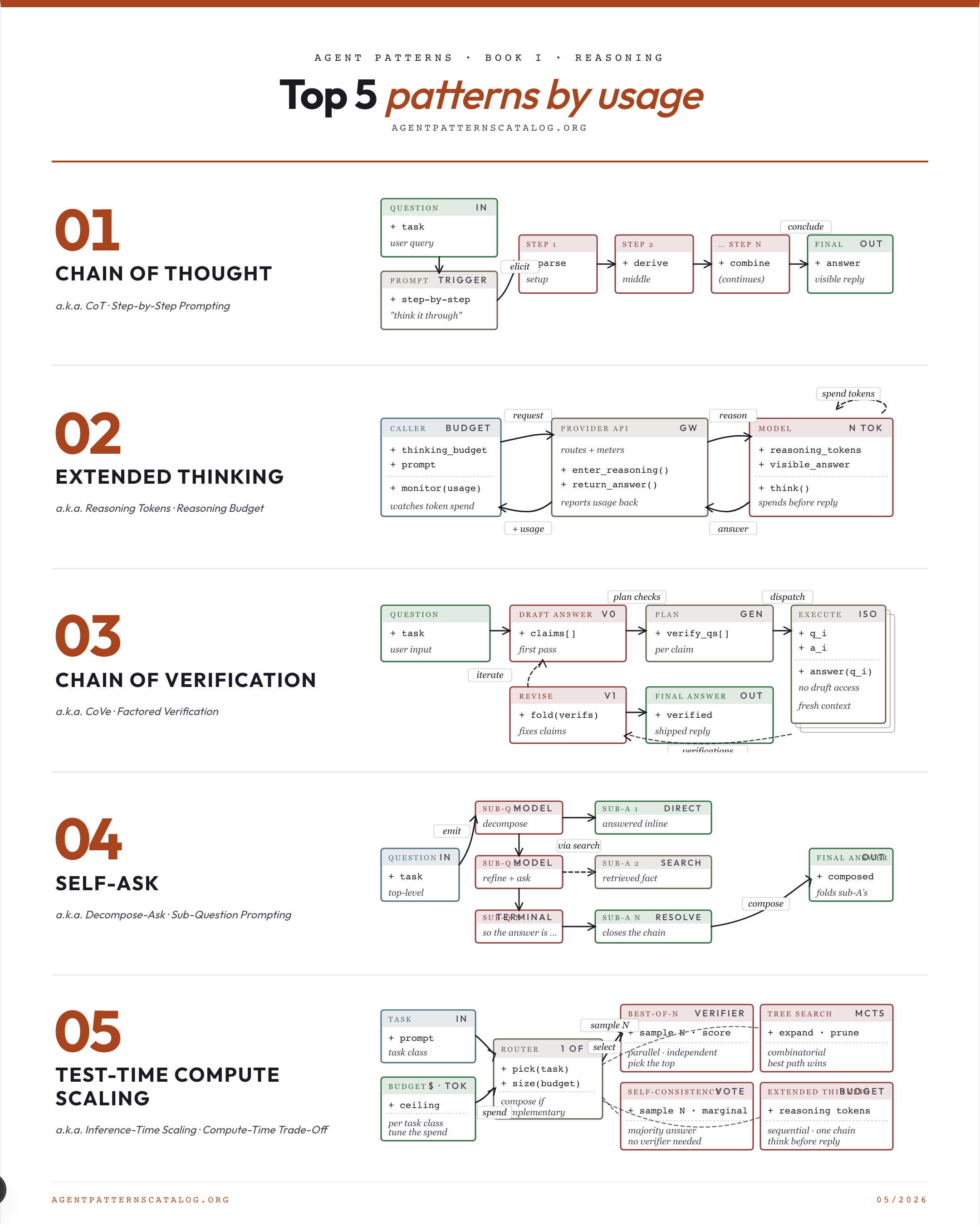
02. Chain of Thought Elicit multi-step reasoning by prompting the model to produce intermediate steps before its final answer. Best for: The task requires multi-step reasoning that single-shot answers fail at. Tradeoff: Single linear trace; no branching or self-correction. Watch for: The task is direct lookup or pattern completion where reasoning steps add no quality.
03. Chain of Verification Reduce hallucination by drafting an answer, generating independent verification questions, answering them in isolation, and revising. Best for: The model hallucinates claims when it self-verifies in the same context as the draft. Tradeoff: 4x baseline cost. Watch for: The task has no factual claims to verify (pure stylistic or generative tasks).
04. Large Reasoning Model (LRM) Paradigm Route reasoning-heavy tasks to a reasoning-tuned model that trades inference time for deliberation, rather than to a fast LLM that exhibits premature-closure. Best for: Mixed task workload with both simple and constraint-heavy queries. Tradeoff: LRM latency unacceptable for some user-facing flows. Watch for: All-fast user-facing flows.
05. Socratic Questioning Agent Drive the agent toward its goal by asking the user a sequence of strategic, open-ended questions that surface the user's own latent knowledge, goal, or context — rather than producing an answer directly. Best for: Tutoring, coaching, and pedagogical workloads where user understanding is the goal. Tradeoff: Slower and more expensive than direct-answer for users who just want an answer. Watch for: Pure information-retrieval tasks where the user just wants an answer.
All patterns in this book
Extended Thinking
×5Spend a configurable budget of internal reasoning tokens before producing a user-visible answer.
Chain of Thought
×4Elicit multi-step reasoning by prompting the model to produce intermediate steps before its final answer.
Chain of Verification
×3Reduce hallucination by drafting an answer, generating independent verification questions, answering them in isolation, and revising.
Large Reasoning Model (LRM) Paradigm
×2Route reasoning-heavy tasks to a reasoning-tuned model that trades inference time for deliberation, rather than to a fast LLM that exhibits premature-closure.
Socratic Questioning Agent
×2Drive the agent toward its goal by asking the user a sequence of strategic, open-ended questions that surface the user's own latent knowledge, goal, or context — rather than producing an answer direc…
Self-Ask
×1Have the model emit explicit follow-up sub-questions, answer them (optionally via search), then compose the final answer.
Test-Time Compute Scaling
×1Allocate more inference-time compute (samples, search, deeper thinking) instead of scaling parameters to improve quality.
Zero-Shot Chain-of-Thought
×1Elicit step-by-step reasoning with a single trigger phrase rather than few-shot exemplars.
Adaptive Compute Allocation
×1Allocate inference-time compute (thinking tokens, samples, depth, model size) per query based on input difficulty, rather than using a fixed budget across all queries.
Attentive Reasoning Queries
×1Replace free-form chain-of-thought with a domain-tailored sequence of structured queries that re-anchor the model's attention to the critical instructions and prior decisions at the exact generation…
Generate-and-Test Strategy
×1Generate multiple candidate solutions in parallel, then systematically test each against declared constraints rather than committing to the first plausible one — adapted from Langley & Simon's cognit…
ReST-EM
×1Iterate generate → reward-filter → fine-tune to bootstrap reasoning capabilities without human-labelled data.
STaR Bootstrapping
×1Bootstrap a model's reasoning by training it on its own correct chain-of-thought outputs.
Tree of Thoughts
×1Search over a tree of partial reasoning states with explicit lookahead, evaluation, and backtracking.
Least-to-Most Prompting
Decompose a hard problem into an ordered list of easier subproblems, then solve them sequentially with each answer feeding the next.
Graph of Thoughts
Model reasoning as an arbitrary DAG so thoughts can be merged, refined, and aggregated across branches.
Latent-Space Reasoning
Let the model reason in continuous hidden-state space instead of decoding each step to text, feeding the last hidden state back as the next input embedding, so one latent step can hold several contin…
Recursive Language Model
Treat an over-long prompt as an environment the model navigates by code, letting it partition and recursively call itself over snippets, so it answers over inputs far larger than its context window.
Trajectory-Summary Test-Time Scaling
When an agent's outputs are extended action-observation trajectories rather than short answers, scale test-time compute by compressing each rollout into a structured summary and selecting or reusing…