Retrieval & RAG
Knowledge from outside parameters.
23 patterns in this book. · Updated
{kind=link}
When to reach for each
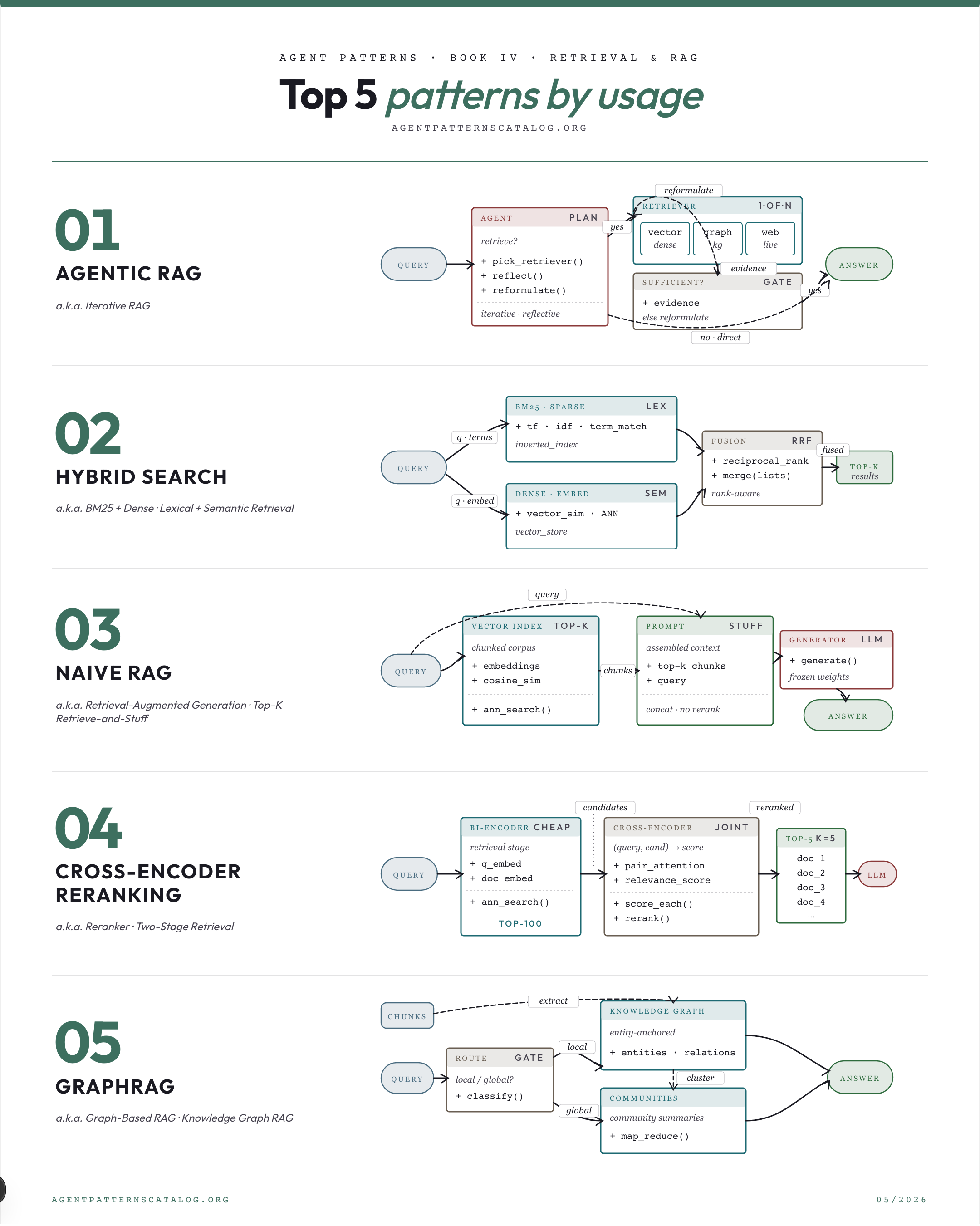
01. Agentic RAG Replace static retrieve-then-generate with autonomous agents that plan, choose sources, retrieve iteratively, reflect, and re-query. Best for: A single retrieve-then-generate pass is insufficient for the task's information needs. Tradeoff: Cost and latency rise with loop iterations. Watch for: Static one-shot RAG already meets quality targets at lower cost and latency.
02. Hybrid Search Combine sparse lexical retrieval (BM25) with dense vector retrieval and fuse the results. Best for: Queries mix semantic intent with rare tokens (codes, IDs, proper nouns) that embeddings miss. Tradeoff: Two indexes to keep in sync. Watch for: The corpus is uniformly conceptual; dense alone is enough.
03. Naive RAG Condition the generator on top-k chunks retrieved from an external dense index so knowledge lives outside parameters. Best for: Knowledge lives outside the model and must be conditioned on at query time. Tradeoff: Chunk boundaries destroy context. Watch for: The needed knowledge is already in a tool, database, or scoped system prompt (see naive-rag-first).
04. Cross-Encoder Reranking After cheap bi-encoder or BM25 retrieval, rescore top-N candidates with a cross-encoder that jointly attends over (query, candidate). Best for: Initial retrieval returns a noisy top-100 and accuracy of top-5 matters. Tradeoff: Latency adds one call per candidate. Watch for: Latency target is sub-100ms end-to-end; cross-encoders blow it.
05. GraphRAG Build an LLM-extracted entity-and-relation knowledge graph plus hierarchical community summaries, then answer global queries via map-reduce over those summaries. Best for: Users ask global, corpus-wide questions that local chunk retrieval cannot answer. Tradeoff: High indexing cost (orders of magnitude more LLM calls). Watch for: Queries are narrowly local and naive RAG already serves them well.
All patterns in this book
Agentic RAG
×53Replace static retrieve-then-generate with autonomous agents that plan, choose sources, retrieve iteratively, reflect, and re-query.
Hybrid Search
×11Combine sparse lexical retrieval (BM25) with dense vector retrieval and fuse the results.
Naive RAG
×9Condition the generator on top-k chunks retrieved from an external dense index so knowledge lives outside parameters.
Cross-Encoder Reranking
×6After cheap bi-encoder or BM25 retrieval, rescore top-N candidates with a cross-encoder that jointly attends over (query, candidate).
GraphRAG
×5Build an LLM-extracted entity-and-relation knowledge graph plus hierarchical community summaries, then answer global queries via map-reduce over those summaries.
Citation Attribution
×4Track and surface, alongside a RAG-grounded answer, which retrieved chunks supported which claims, so the binding between answer span and source survives all the way to the user.
Contextual Retrieval
×4Prepend a short LLM-generated description to each chunk before embedding so the chunk carries its situating context.
Repo Map
×4Give the agent a compact, ranked map of the codebase's symbols and their dependencies so it orients on what matters before reading any files.
Query Rewriting
×3Use an LLM to generate several alternative formulations of the user's query, retrieve documents for each, and rank-fuse the results so recall does not depend on one phrasing.
HippoRAG
×3Build an LLM-extracted schemaless knowledge graph from the corpus and run Personalized PageRank seeded on the query's key concepts so multi-hop retrieval completes in a single pass.
Semantic Response Cache
×3Embed each query and, when its nearest cached neighbour is within a similarity threshold, return the stored answer instead of re-running the model so near-duplicate questions are answered cheaply.
Streaming Feature Pipeline
×3Process raw documents into RAG features as a continuous stream rather than a batch job, with typed models pinning each stage.
CDC-Driven Vector Sync
×2Treat the source-of-truth document store as the only writer; keep the vector index in sync by emitting change-data-capture events onto a queue that the feature pipeline consumes.
CRAG
×2Add a lightweight retrieval evaluator that grades each retrieved document and triggers corrective web search on poor retrievals.
HyDE
×2Have the LLM write a hypothetical answer document, embed it, and use it as the retrieval query.
Modular RAG
×2Decompose RAG into a typed three-layer hierarchy of Module Types, Modules, and Operators so the pipeline (routing, scheduling, fusion, retrieval, post-retrieval, generation) can be rearranged per que…
RAFT
×2Train the model to ignore irrelevant retrieved documents (distractors) in a domain-specific RAG setting.
Hierarchical Retrieval
×1Route a query through a multi-level cascade — coarse source or index selection, then per-source narrower retrieval, then chunk-level — so each retrieval decision is pushed to the cheapest tier that c…
Self-RAG
×1Fine-tune the model to emit reflection tokens that decide when to retrieve, evaluate retrieved relevance, and assess generated support.
Table-Augmented Generation
×1Answer a natural-language question over a database in three stages — synthesise an executable query, run it against the data layer with model calls embedded in execution, then generate the answer fro…
Vectorless Reasoning-Based Retrieval
×1Retrieve by having the model reason its way down a document's own table-of-contents tree to the relevant sections, instead of embedding chunks and ranking them by vector similarity.
Tacit-Knowledge Elicitation Agent
Run a front-loaded phase in which an agent interviews domain experts and converts their undocumented know-how into a structured, queryable knowledge base before downstream task agents read from it.
Dependency-Aware Skill Retrieval
Retrieve from a large skill library by returning each relevant skill together with its prerequisite dependency closure as an ordered subgraph, so the bundle the agent receives is executable rather th…