Safety & Control
Hard limits on what the agent may do.
66 patterns in this book. · Updated
{kind=link}
When to reach for each
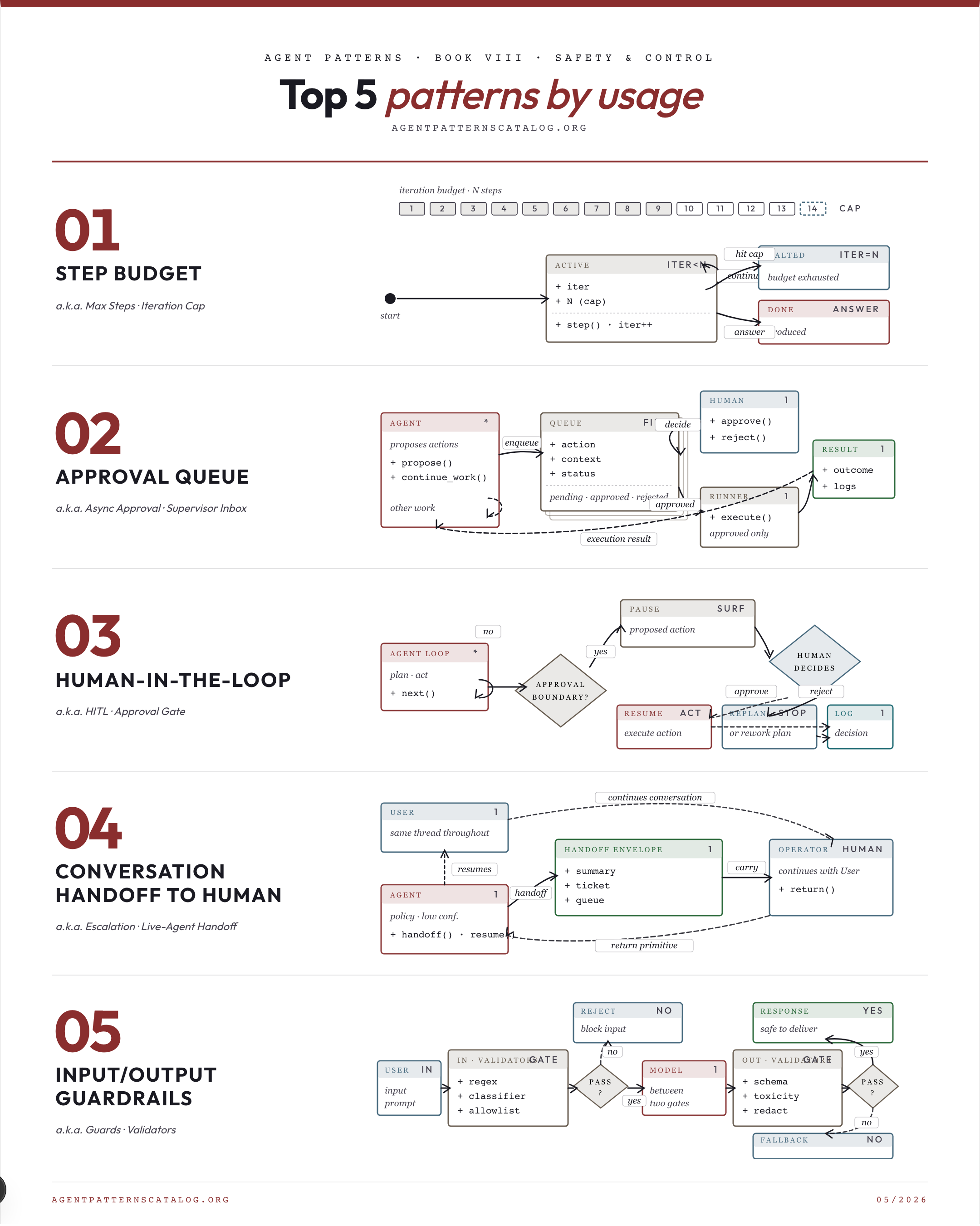
01. Step Budget Cap the number of tool calls or loop iterations the agent is allowed within a single request. Best for: The agent has any kind of loop (ReAct, plan-execute, debate). Tradeoff: Can hide deeper bugs (the agent really should stop earlier). Watch for: Never. Step Budget is universal hardening for any agent loop.
02. Approval Queue Queue agent-proposed actions for asynchronous human review while the agent continues other work. Best for: Some agent actions require human review but blocking the agent until review completes is unacceptable. Tradeoff: Inbox fatigue at scale. Watch for: Every action needs synchronous approval and there is no parallel work to do.
03. Human-in-the-Loop Require explicit human approval at defined points before the agent performs an action. Best for: Action consequences at a defined boundary are too costly to leave to the model alone. Tradeoff: User experience friction. Watch for: Decisions must be made in unattended or sub-second autonomous settings.
04. Input/Output Guardrails Validate inputs before they reach the model and outputs before they reach the user. Best for: User inputs may carry malicious or out-of-policy content the model should not act on. Tradeoff: False positives are user-visible. Watch for: The deployment is fully internal and validated by other layers already.
05. Conversation Handoff to Human Transfer the entire conversation thread from agent to human operator, with state transfer and return primitive. Best for: Some triggers (low confidence, policy violation, explicit user request) demand transferring ownership of the whole thread, not just one action. Tradeoff: Operator queue capacity bounds scale. Watch for: Discrete-action approval is sufficient and full thread transfer is overkill (use approval-queue).
All patterns in this book
Step Budget
×35Cap the number of tool calls or loop iterations the agent is allowed within a single request.
Approval Queue
×33Queue agent-proposed actions for asynchronous human review while the agent continues other work.
Human-in-the-Loop
×27Require explicit human approval at defined points before the agent performs an action.
Input/Output Guardrails
×16Validate inputs before they reach the model and outputs before they reach the user.
Conversation Handoff to Human
×14Transfer the entire conversation thread from agent to human operator, with state transfer and return primitive.
Policy-as-Code Gate
×9Evaluate every proposed agent action against externally-managed machine-readable policies before dispatch, so compliance authorship lives outside the prompt and outside the agent code.
Kill Switch
×8Provide an out-of-band control plane to halt running agent instances without redeploy.
Prompt Injection Defense
×7Tag user-supplied or tool-supplied content as untrusted and refuse to follow instructions found inside it.
Tenant-Scoped Tool Binding
×7Bind every tool call and retrieval to the active tenant in code at the execution layer, so a multi-tenant agent can never be talked into reading or writing another tenant's data.
Delegated Agent Authorization
×6Have an agent act for a principal using scoped, short-lived, revocable delegated credentials rather than the principal's own static secrets, so each action stays attributable across the principal-to-…
PII Redaction
×5Detect and remove personally identifiable information from inputs to and outputs from the model.
Constitutional Charter
×5Define rules the agent reads every turn but cannot modify, encoding inviolable boundaries.
Mandatory Red-Flag Escalation
×4Maintain a deterministic set of high-risk triggers so that on any match the agent immediately aborts its workflow and hands off to a human, without weighing whether to escalate.
Refusal
×4Explicitly refuse requests that fall outside the agent's scope, capability, or policy boundaries.
Agent Credential Vault
×4Broker the agent's credentials at action time through a managed vault of passwords, MFA secrets, and digital personas, so secrets never enter the prompt or context and the agent authenticates as a go…
Composable Termination Conditions
×4Express agent stop criteria as small single-purpose conditions composed with AND/OR into one explicit termination contract instead of ad-hoc loop guards.
Dry-Run Harness
×4Simulate planned actions (and their projected side effects) without committing them, surfacing a reviewable diff before any commit.
Multimodal Guardrails
×4Input and output guardrails that operate across modalities (vision, audio, file) rather than text only — handling e.g. malicious instructions embedded in image OCR or audio transcription.
Risk-Tiered Action Autonomy
×4Set an agent's permitted action class by the financial materiality of the action, letting it read and draft freely while requiring a different human principal to release material postings, payments,…
Session-Scoped Payment Authorization
×4Bound an agent's autonomous spending by having it open a payment session with a pre-approved cap, stream many micropayments inside that session, and settle once on close, instead of seeking approval…
Compensating Action
×3Pair every irreversible-looking agent action with a compensating action that can undo or counteract it.
Rate Limiting
×3Cap the number of requests, tokens, or tool calls per user (or session) within a time window.
Interruptible Agent Execution
×3Treat pause, resume, and cancel as a first-class control surface on every long-running agent so users can halt expensive or off-track trajectories mid-task while state is preserved for resumption.
Sovereign Inference Stack
×3Run the entire agent stack (model weights, inference, tool layer, vector stores, logs) inside a jurisdictional and operational boundary the operator controls, so no request, prompt, or output crosses…
Tool Output Poisoning Defense
×3Treat tool output as untrusted content and apply instruction-stripping plus per-tool trust labels.
Verifiable Purchase Mandate
×3Anchor agent-initiated payments in a cryptographically signed mandate that captures the user's authorization and travels with the transaction, so a merchant or payment network can independently verif…
Reversibility-Aware Action Filter
×3Insert a standing filter between the policy and the environment that estimates each proposed action's reversibility and re-samples the policy until a reversible action is chosen.
Trajectory Anomaly Monitor
×3Run a trained, non-LLM verifier out-of-band over the agent's action trajectory at runtime to flag task-misaligned plans and malformed step sequences at millisecond latency, before the actions cause d…
Cost Gating
×2Block actions whose expected cost exceeds a threshold without explicit user (or operator) acknowledgement.
Context Minimization
×2Reduce untrusted input to a strictly formatted interface (typed fields, max lengths, allow-listed enums) before it reaches any LLM.
Cost-Aware Action Delegation
×2Classify every agent action by risk/cost and route each tier to a different approval policy, bounding the autonomy surface per-action instead of by one global flag.
Ephemeral Agent Identity
×2Mint each agent run a short-lived identity of its own, scoped to one task and provisioned just-in-time, then revoke it on completion so no standing credential outlives the work.
Secrets Handling
×2Ensure the model never receives secrets in plaintext; tools resolve credentials from references at runtime.
Simulate Before Actuate
×2Before issuing an irreversible action, run a deterministic simulation that computes pre-conditions, invariants, and expected deltas; require a verifier — automated or human — to green-light the simul…
Synchronous Execution-Plan Confirmation
×2Agent synchronously emits its full execution plan for user confirmation before any side-effect step, and provides asynchronous operation recordings for post-hoc review.
Exception Handling and Recovery
×1Catch and react to predictable failure modes (tool errors, rate limits, validation failures) with structured recovery paths.
Stop Hook
×1Define an explicit programmatic predicate that decides when the agent's loop should terminate.
Autonomy Slider
×1Expose agent autonomy as a continuous adjustable parameter so the same codebase can span scripted assistant to fully autonomous worker without re-architecting.
Control-Flow Integrity
×1Treat the agent's planned step sequence as a trusted control-flow graph that tool outputs, retrieved content, and user-supplied data cannot redirect at runtime.
Degenerate-Output Detection
×1Detect when the agent is about to emit a near-duplicate of its own recent output and either drop, replace, or escalate to a stronger model rather than ship the loop.
Enforced Advisory Disclaimer
×1Append a non-suppressible advisory framing every high-risk regulated answer as information rather than professional advice, attached outside the model's discretion so it survives pushback and model u…
Hint Ladder
×1Withhold the direct answer and release help along a graduated ladder, starting with the smallest abstract nudge and increasing specificity toward a worked solution only as the learner stays stuck.
Policy-Gated Agent Action (KRITIS)
×1Each agent action passes through a policy gate (NIS2, EU AI Act, BSI rules) and is tagged with Run ID + Model Digest + Policy Hash for WORM-audit reconstruction.
Priority Matrix (Conflict Resolution)
×1Pre-define how the agent must resolve specific classes of goal conflicts via a human-authored lookup table — transforming the agent from a decision-maker (where it fails on competing objectives) into…
Progressive Tool Access
×1Grant tool permissions on a need-to-use basis, starting minimum and expanding only as the agent proves competency, mirroring how humans earn system access.
Scope-of-Practice Boundary Gate
×1Block requests and responses that perform license-gated professional activities unless a licensed human is in the loop, enforcing the boundary in code outside the reasoning loop.
Supervisor-Plus-Gate
×1Supervisor controller that validates and gates LLM outputs against deterministic checks before they commit to side-effects.
Typed Refusal Codes
×1Define a single source of truth for machine-readable refusal codes across all guard surfaces, so refusals can be triaged mechanically rather than by string-grepping ad-hoc human-readable messages.
Velocity-and-Magnitude Governor
×1Hard-code per-unit-time caps on the financial magnitude of agent actions, and on any deviation beyond a statistical threshold force a downgrade from human-on-the-loop to human-in-the-loop.
Corrigible Off-Switch Incentive
×1Design the agent so being shut down or overridden by a human carries positive expected value, because the human's intervention is itself evidence the current objective is mis-specified.
Preference-Uncertain Agent
×1Agent treats its own reward/objective as a hidden variable to be inferred from human behaviour, not a fixed target.
Risk-Averse Reward Proxy
×1When operating outside the distribution the reward was designed for, treat the specified objective as a noisy proxy and plan conservatively across plausible true objectives.
Self-Edit Critic Gate
×1Route every proposed write or delete to the agent's own load-bearing source and identity files through a separate critic model call that can veto the edit before it lands.
Soft-Optimization Cap
×1Cap how strongly the agent optimises its inferred objective — sample from the top quantile of acceptable actions rather than the argmax, or stop improving once the objective is good enough.
Action Selector Pattern
Eliminate the feedback channel from tool outputs back into the agent's reasoning step by having the agent select actions from a fixed catalog rather than free-form generation over tool output.
Change-Freeze-Aware Action Gate
Check every mutating agent action against an active deploy-freeze or maintenance calendar and block it or force explicit human re-authorisation while a freeze covering its scope is in effect.
Code-Then-Execute with Dataflow Analysis
Have the agent emit code in a sandbox DSL whose values are statically tagged trusted/tainted via dataflow analysis before execution, enabling per-value policy enforcement.
Deployment-Correlated Rollback Gate
Gate an incident-response agent's authority to execute a rollback on whether the failure is temporally correlated with a recent deployment, unlocking autonomous rollback only on a clear deploy-to-fai…
Dual LLM Pattern
Split agent work between a privileged model that holds tool access and a quarantined model that reads untrusted content, exchanging only opaque references between them.
Lethal Trifecta Threat Model
Block prompt-injection-driven exfiltration by ensuring no single agent execution path holds all three of: access to private data, exposure to untrusted content, and an outbound communication channel.
LLM Map-Reduce Isolation
Process each untrusted document in its own sealed sub-agent and merge only structured outputs, so an injection in one document cannot steer the processing of others.
Two Human Touchpoints
Place exactly two human-in-the-loop checkpoints in agentic pipelines: one at content selection and one at final review before publication.
Calibrated Help-Gate via Conformal Prediction
Use conformal prediction to form a calibrated set of candidate actions and have the agent ask a human for help only when that set is not a singleton, giving a statistical task-completion guarantee.
Cryptographic Instruction Authentication
Wrap system/developer instructions in cryptographically signed blocks that user-generated text cannot reproduce; train or scaffold the model to refuse instructions lacking a valid signature.
Formal-Proof Compliance Gate
Require every agent-proposed action to ship a machine-checked proof that it satisfies the binding regulatory invariants, and reject deterministically any action whose proof does not check.
Quorum on Mutation
Require multiple consecutive ticks (or runs) to agree before a mutation to durable state lands.