Structure & Data
Shape of inputs, outputs, artefacts.
10 patterns in this book. · Updated
{kind=link}
When to reach for each
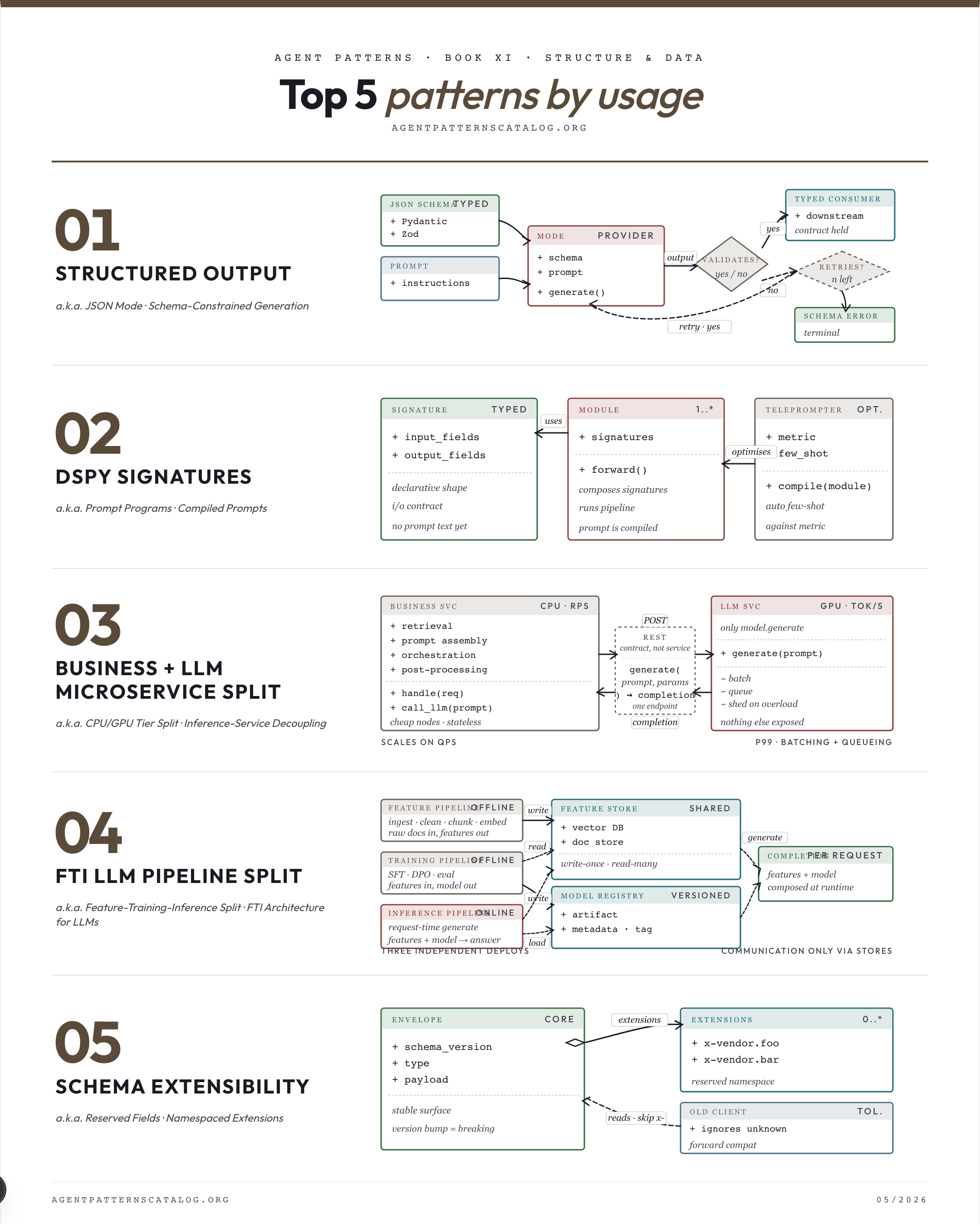
01. Structured Output Constrain the model's output to conform to a JSON Schema (or similar typed shape). Best for: Downstream code consumes typed data and free-form text would break parsers. Tradeoff: Provider lock-in for the strictest modes. Watch for: Output is for human consumption only and structure adds no value.
02. Channel-Decoupled Agent Core Put the agent's reasoning, tools, and session state behind channel-agnostic ports, and make each delivery surface (web, voice, email, Slack, background jobs) an adapter, so one core serves every channel. Best for: The same agent must run across more than one delivery surface (web, voice, email, chat apps) or across both live and unattended modes. Tradeoff: The normalized contract is a design bottleneck: a channel feature it cannot express (streaming tokens, rich attachments, voice interruption) is hard to surface without leaking channel specifics into the core. Watch for: The agent serves exactly one channel and there is no foreseeable second surface, so the adapter layer is pure overhead.
03. DSPy Signatures Specify agent behaviour as declarative typed signatures and modules; compile prompts and few-shot examples automatically against a metric. Best for: Hand-crafted prompts are brittle and drift across model versions. Tradeoff: Compilation requires labelled or auto-evaluable data. Watch for: The pipeline is a single prompt and the DSPy machinery is overkill.
04. Business + LLM Microservice Split Split an LLM application into a CPU-bound business microservice (retrieval, prompt assembly, orchestration) and a GPU-bound LLM microservice (only model.generate behind REST), so each tier scales on its own hardware budget. Best for: LLM inference and business logic have diverging scaling profiles. Tradeoff: One extra network hop per LLM call — latency cost. Watch for: Very low traffic — one service is simpler and within budget.
05. FTI LLM Pipeline Split Decompose an LLM/RAG system into three independently-deployable pipelines — feature, training, inference — communicating only via a feature store and a model registry. Best for: Feature, training, and inference have materially different cadences and ownership. Tradeoff: Two integration surfaces to operate and version. Watch for: System is small enough that one repository and one deploy cycle is fine.
All patterns in this book
Structured Output
×52Constrain the model's output to conform to a JSON Schema (or similar typed shape).
Channel-Decoupled Agent Core
×3Put the agent's reasoning, tools, and session state behind channel-agnostic ports, and make each delivery surface (web, voice, email, Slack, background jobs) an adapter, so one core serves every chan…
DSPy Signatures
×3Specify agent behaviour as declarative typed signatures and modules; compile prompts and few-shot examples automatically against a metric.
Business + LLM Microservice Split
×1Split an LLM application into a CPU-bound business microservice (retrieval, prompt assembly, orchestration) and a GPU-bound LLM microservice (only model.generate behind REST), so each tier scales on…
FTI LLM Pipeline Split
×1Decompose an LLM/RAG system into three independently-deployable pipelines — feature, training, inference — communicating only via a feature store and a model registry.
Polymorphic Record
×1Represent a family of related entities in a single core schema with type-specific extensions.
Prompt/Response Optimiser
×1At runtime, transform user inputs and model outputs into standardised, template-aligned prompts and responses against predefined constraints, so the agent and its downstream consumers see consistent…
Schema Extensibility
×1Build schemas that evolve without breaking old clients via reserved namespaces and extension blocks.
Code-Switching-Aware Agent
×1Treat mixed-language input (e.g. Hinglish in Roman script) as the expected shape, and design tokenisation, language tagging, and tool routing to handle it natively without forcing the user to commit…
LLM as Periphery
Invert the typical LLM-in-the-middle architecture: a deterministic state machine and event store form the core; the LLM is restricted to edge tasks — input interpretation and output synthesis only.