Verification & Reflection
Catching the model's mistakes.
29 patterns in this book. · Updated
{kind=link}
When to reach for each
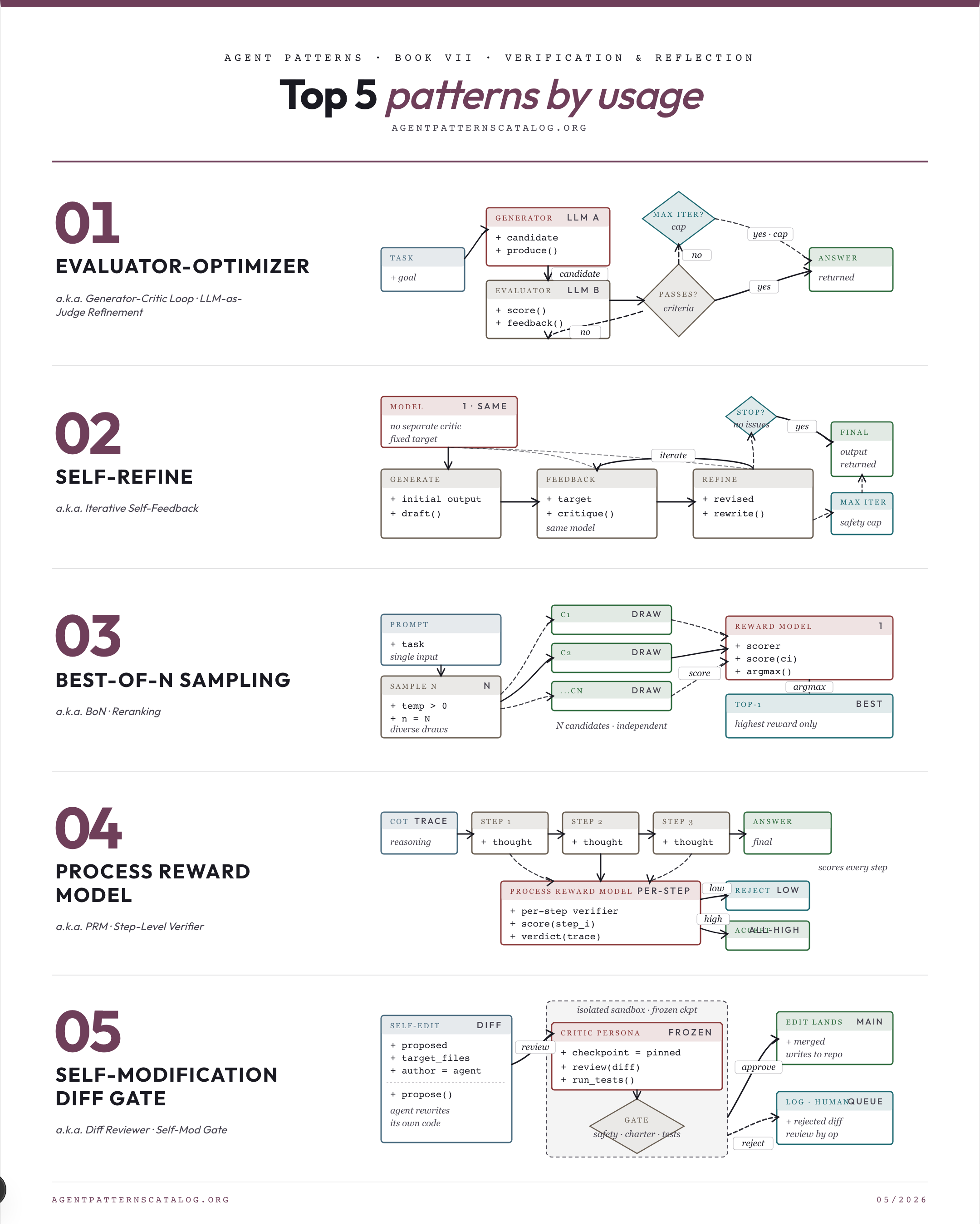
01. Evaluator-Optimizer One LLM generates; another evaluates and feeds back; loop until criteria are met. Best for: Single-shot generation tops out below the quality the task requires. Tradeoff: Cost = (generator + evaluator) x iterations. Watch for: Single-shot generation already meets quality targets.
02. Self-Refine Iterate generate → feedback (same model) → refine until a stop criterion fires, with no separate critic model. Best for: The same model can produce useful self-feedback against an explicit improvement target. Tradeoff: Reinforces same-model blind spots (Reflexion replication studies). Watch for: A different model family is available and would give independent critique.
03. Best-of-N Sampling Sample N candidate outputs and select the highest-ranked by a reward model or scorer. Best for: A scorer or reward model exists that ranks candidates better than the generator picks them. Tradeoff: Cost scales with N. Watch for: No reliable scorer is available to pick among candidates.
04. Reflection Have the model review its own output and produce a revised version in one or more passes. Best for: One-shot generation underuses the model and a critique pass would catch errors. Tradeoff: Diminishing returns after one or two passes. Watch for: The model already produces correct outputs in one pass.
05. Confidence Reporting Surface the agent's uncertainty about its answer alongside the answer itself. Best for: Downstream code or UI needs to distinguish 'I know' from 'I am guessing' on each answer. Tradeoff: Calibration is empirical and drifts. Watch for: Confidence labels would be ignored by both the UI and the routing layer.
All patterns in this book
Evaluator-Optimizer
×6One LLM generates; another evaluates and feeds back; loop until criteria are met.
Self-Refine
×6Iterate generate → feedback (same model) → refine until a stop criterion fires, with no separate critic model.
Best-of-N Sampling
×5Sample N candidate outputs and select the highest-ranked by a reward model or scorer.
Reflection
×3Have the model review its own output and produce a revised version in one or more passes.
Confidence Reporting
×3Surface the agent's uncertainty about its answer alongside the answer itself.
Process Reward Model
×3Train a verifier that scores each reasoning step rather than only the final answer.
Self-Modification Diff Gate
×3Gate the agent's edits to its own code or rules through a separate critic persona that reviews the diff before it lands.
Prompt Variant Evaluation
×2Author multiple variants of the same prompt node, run them as a batch against a shared dataset, and let an automated evaluation flow score them so the winning variant is selected by measurement.
Dimensional Synthetic Eval Set
×2Generate evaluation inputs not by free-form LLM prompting (which mode-collapses) but by enumerating tuples over explicitly named dimensions and seeding generation from each tuple.
Frozen Rubric Reflection
×2Constrain reflection to a fixed, hand-authored rubric of criteria so the reviewer cannot invent new ones each run.
Tool-Augmented Self-Correction
×2Self-correct LLM outputs by interactively critiquing them with external tools (search, code execution, calculator).
Reflexion
×2Have the agent write linguistic lessons from past failures and consult them in future episodes.
Self-Consistency
×1Sample the same question multiple times at non-zero temperature and aggregate by majority or judge to mitigate hallucination.
Behavior-Pinning Test Before Agent Edit
×1Capture the current behaviour of agent-touchable code as golden characterization tests before an agent edits it, with load-bearing values computed deterministically and only prose left to the model,…
Blind Grader with Isolated Context
×1Run an evaluator in a separately-allocated context window with access only to the artifact and the rubric, never the producing agent's reasoning trace, so the grader cannot be primed by the producer'…
Cross-Reflection
×1Reflection step performed by a *different* agent or foundation model from the original generator, so critique error is decorrelated from generation error.
Deterministic-LLM Sandwich
×1Bracket every LLM call with deterministic checks on both sides.
Generator-Critic Separation
×1Strict role separation between a Generator agent that produces drafts and a Critic agent that judges them against pre-defined criteria; the Critic never generates.
Human Reflection
×1Reflection loop that explicitly collects human feedback (not approval) on agent plans to improve them, distinct from approval gates where the human only says yes/no.
Red-Team Sandbox Reproduction
×1Routinely re-reproduce canonical alignment-failure modes inside a sealed sandbox per release; treat the alignment regression suite as a deployment gate.
Stochastic-Deterministic Boundary (SDB)
×1Formalize the seam between an LLM proposal and a system action as a four-part contract — proposer, verifier, commit step, reject signal — so the contract itself, not the agent's good intent, gates si…
Verify-Before-Cite Resolution Gate
×1After generation, resolve every cited authority against an external ground-truth registry and strip or block any citation that does not exist before the answer reaches the reader.
Agentic Context Engineering Playbook
×1Treat the agent's system prompt and long-lived memory as a structured, item-addressable playbook that evolves through small delta updates from a Generator/Reflector/Curator loop, so accumulated tacti…
Commitment Tracking
×1Extract stated intents from each agent turn into a structured ledger with open / followed-through / expired status, making the gap between promise and follow-through visible and auditable.
Darwin-Gödel Self-Rewrite
×1An agent rewrites its own source code, archives every successful variant, and samples mutation parents from the archive rather than the latest version, using archive diversity as stepping-stones to e…
Echo Recognition
×1Recognize human message repetition as emphasis or a re-ask rather than as an independent input, so the agent does not produce a near-duplicate reply when the human repeats themselves.
World Model as Tool
×1Let a planning agent invoke a generative world model as a tool to roll out hypothetical futures before committing to an action, treating the world model as a callable simulator rather than a training…
Confidence-Checking Workflow
Always ask the agent, for each part of its output, to state its confidence and identify which parts need human verification, like triaging a junior analyst's work.
Planner-Executor-Verifier (PEV)
Triadic specialization where a planner produces the plan, an executor runs it, and a separate verifier checks each step's effects against the original goal.